This article teaches you how to quickly install, setup and run DeepSeek R1 large language models (LLMs) in under 30 minutes on your local computer with minimal configuration. This variant when installed from online sources can run local without any internet access. It allows you to keep your output data private, perfect for offline AI tasks like chatbots, summarization, or localised AI processing. Do note the instructions here are not exclusive to Deepseek and applicable to other large language models like OpenAI, Llama or WizardLM.
An efficient LLM marvel
In a nutshell, DeepSeek R1, introduced in January 2025 by the Chinese AI startup DeepSeek, has rapidly gained prominence in the artificial intelligence community. This open-source reasoning model distinguishes itself by achieving performance comparable to leading AI systems. It is comparable to OpenAI’s o1, while utilizing less sophisticated hardware and reduced computational resources. DeepSeek R1 employs reinforcement learning techniques, enabling it to excel in complex tasks like mathematical problem-solving and coding. Also, its architecture activates only the relevant networks in response to specific prompts, significantly enhancing efficiency.
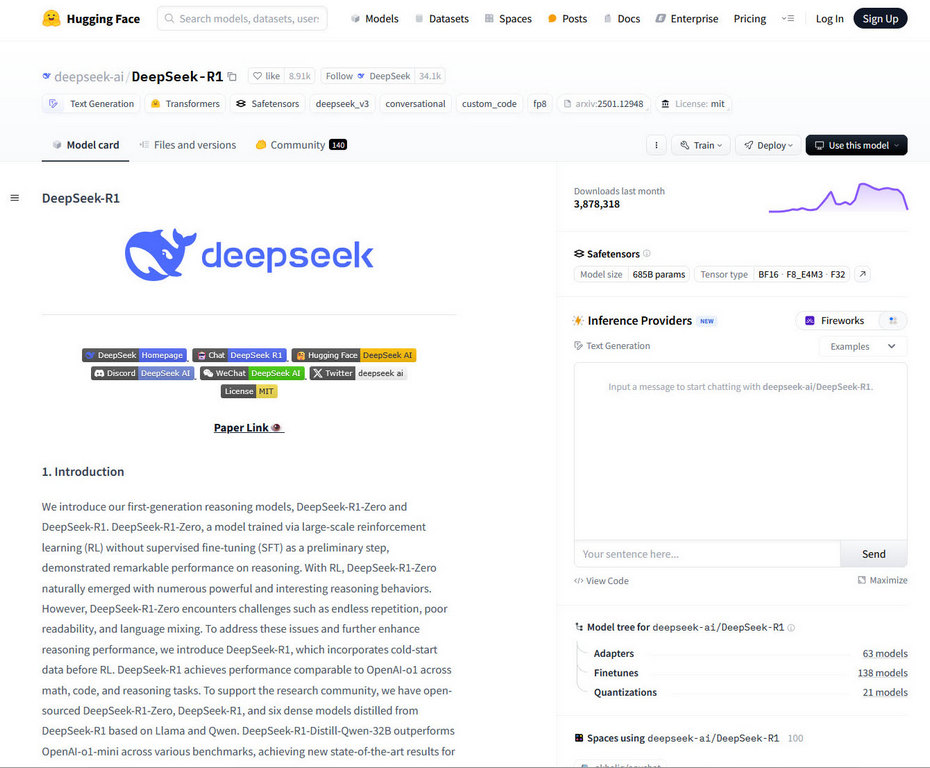
The model’s rise to fame can be attributed to its accessibility and cost-effectiveness. By releasing DeepSeek R1 under the MIT License, the company has encouraged widespread adoption and adaptation across various industries. Notably, financial institutions such as Tiger Brokers have integrated DeepSeek R1 into their operations, enhancing market analysis and trading capabilities. This widespread adoption has not only disrupted traditional AI investment landscapes but also positioned DeepSeek as a formidable contender in the global AI arena.
It is also worth noting that further stripped-down versions of DeepSeek RI are lean enough to run even on small ARM-based systems like Raspberry pi or even on your mobile phone for instance. However, the quality of the output and token throughput performance is sub-par compared to running on PC hardware.
Large Language models explained
First off, some background of large language models (LLMs). These typically requires lots of computing power, particularly GPU compute and video RAM (VRAM) to create. Typically, these models require cross inference and combining of various models which outputs a model file. The system requirements to run these compiled models is typically lower and can be adequately run on consumer PC hardware.
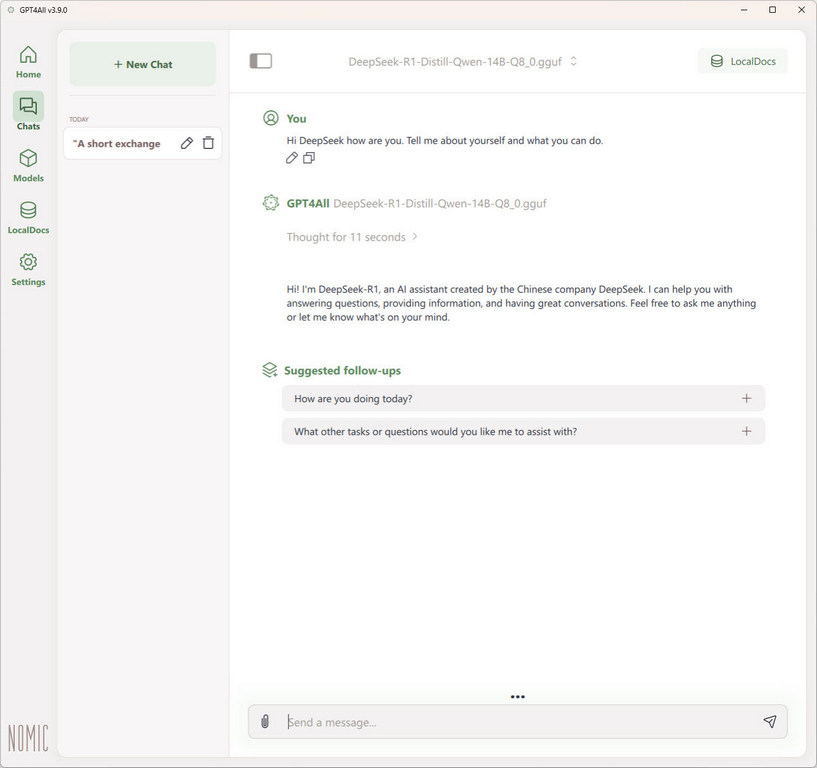
We are going to use nomic-Ai’s GPT4All, a graphical user interface LLM package which you can simply just download and install without having to build an extensive development environment or install runtimes. GPT4All is attractive as it does all these for you in one installer package app.
System requirements
Hardware-wise, you need a dedicated GPU with at least 8GB of video ram (VRAM) to run a basic model. You are often more GPU-bound than CPU bound here. The model you could run with 8GB VRAM is mostly limited to 7B (7-billion parameters) with 4-bit quant models.
Moreover, if you have a video card with 16GB of VRAM (e.g Nvidia 4060Ti, AMD 7800XT, Intel Arc A770), you have the option to opt for larger 13B models. Here you get benefits of better context and larger number of parameters give the model more “general knowledge” with better and smarter outputs.
Additionally, the model file GPT4All typically uses has a .GGUF file extension, GGUF formats allow you to easily split the model between GPU VRAM and CPU RAM. Here, a modern CPU, e.g. Intel 9-gen or Ryzen 5000 series desktop CPU and above with at least 16GB system RAM and at least 32GB if you plan to off-load the model out of the GPU into CPU.
Moreover, using GGUF files lets you run Deepseek R1 on lower-end hardware efficiently while keeping good performance. Like GPT4All, KoboldCpp is another GUI alternative. There are also other command line alternatives like llama.cpp.
Obtaining the Deepseek R1 model
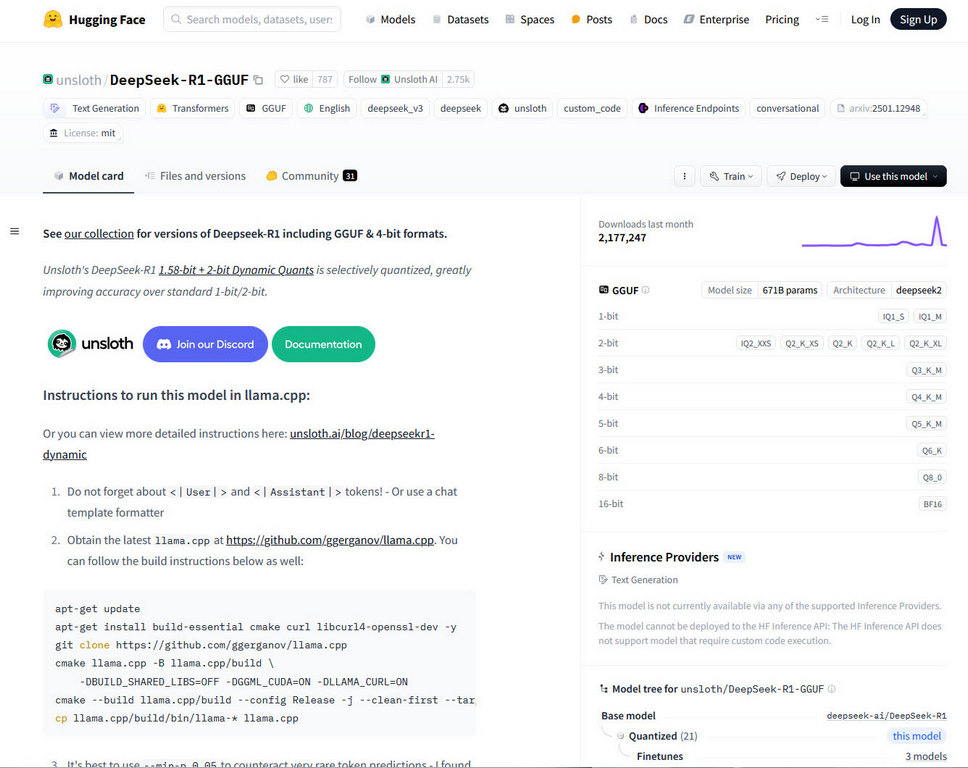
To run on you need your model. Next to obtaining the Deepseek model. Hugging face is a nice place to download the model, recommend searching for a model using keywords “DeepSeek R1 7B GGUF” if you have 8GB VRAM and “DeepSeek R1 13B GGUF”. On your search on Hugging face, it is worth noting too there are also uncensored or “obliterated” models which does not have guardrails removed, so use with caution.
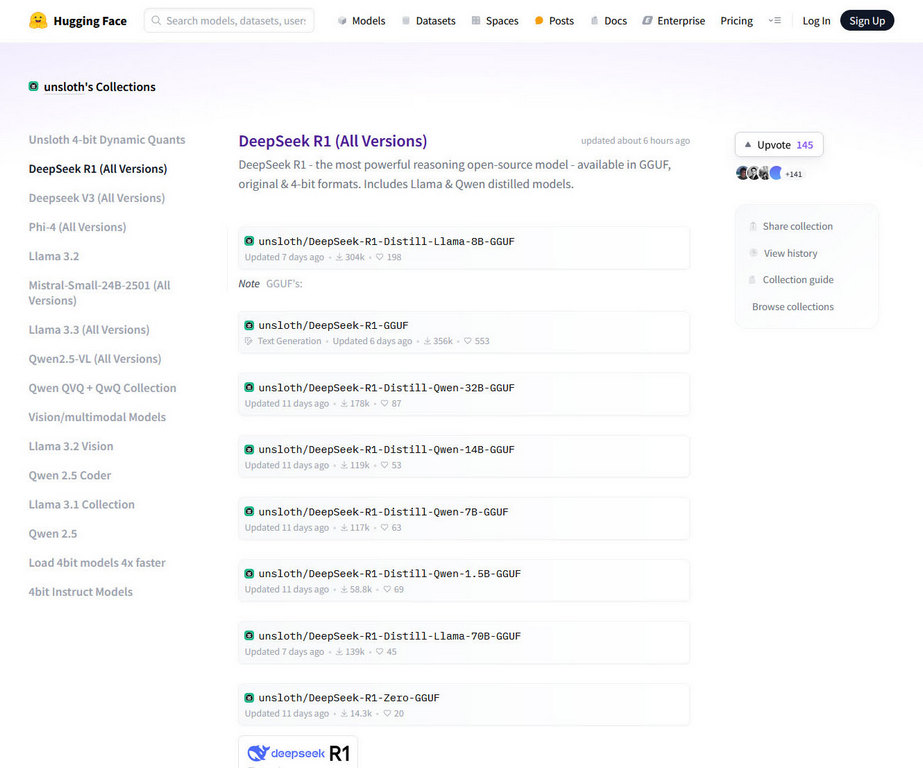
You can download it via the URL:
After downloading the models, typically in the 8GB size of 7B and 14-15GB for 13B models, place your downloaded model file into the GPT4All Appdata folder depending on your operating system and start GPT4All and query away:
Mac: /Users/{username}/Library/Application Support/nomic.ai/GPT4All/
Linux: /home/{username}/.local/share/nomic.ai/GPT4All
Bits and Quantization explained
With the model running, you can experiment with different model parameters to suit your needs. Besides parameter count, you might notice a “bit parameter”, with a choice of 1-Bit to 8-Bit Quantization. In general, you would want higher quants as it gives higher quality outputs, but at VRAM cost.
A general recommendation is to stick to 4-bit precision (e.g. Q4_K_M for 4-bit Quantization K-Matrix format) and work your way up (e.g. Q5_K_M, and Q8_0) if your system has enough VRAM to support a decent token/s performance of 10-20 tokens per second.
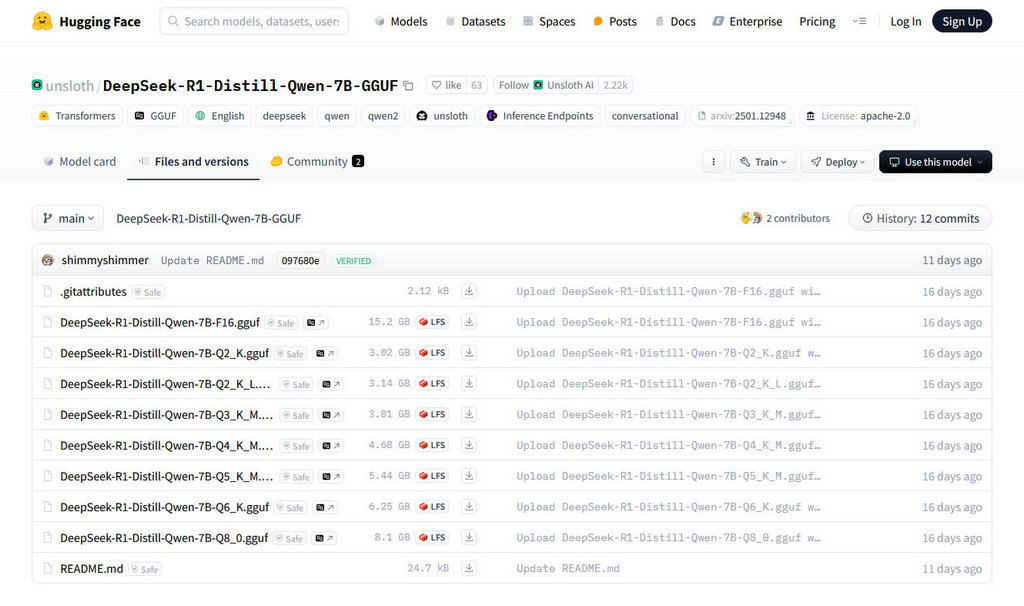
Also, the “K” suffix in some model variants refers to a more efficient grouped quantization strategy. “M” typically denotes a mixed precision approach that improves accuracy. Mixed precision offers significant memory savings, allowing for faster inference and lower VRAM usage. The downside however, is slightly lower numerical precision may lead to some performance degradation in reasoning tasks.
Q4_K_M: Best for low-end hardware (like consumer GPUs) where speed and memory savings matter more than accuracy. Recommended for most users for balance.
Q5_K_M: A balanced choice for mid-range systems with little to almost no loss of perplexity, providing better accuracy while still optimizing memory usage.
Q8_0: Best for high-end GPUs where maximum accuracy is needed, such as for critical reasoning tasks.
If you have a good system with 8GB VRAM, I recommend download at least the 7B Q4K_M quant file. It has a good balance of size to quality. Likewise, if you have a top-end 4090Ti with 24GB VRAM, you can handle up to 30B Q4K_M models. Here is a handy chart of the models you can run given amount of VRAM and assuming 4bit quants:
13B: At least 10GB, though 12 is ideal
30-33B: At least 24GB
40B: Around 28GB minimum
65B: Around 40GB minimum
Tweaking and refining the model output
You model may exhibit some quirky behaviors like text repetition and producing shorter outputs than expected. You can tweak the performance and output of your model on the settings page. Configuration general guidance for “context length” and “max length” is about 1 token per word. Hence, if you wish to have a 2000-word story written, your output tokens should be set to be at least 2000-2500 token range. The same rule applies for input characters too, where 2000 tokens should be adequate for a 2000-word input prompt.
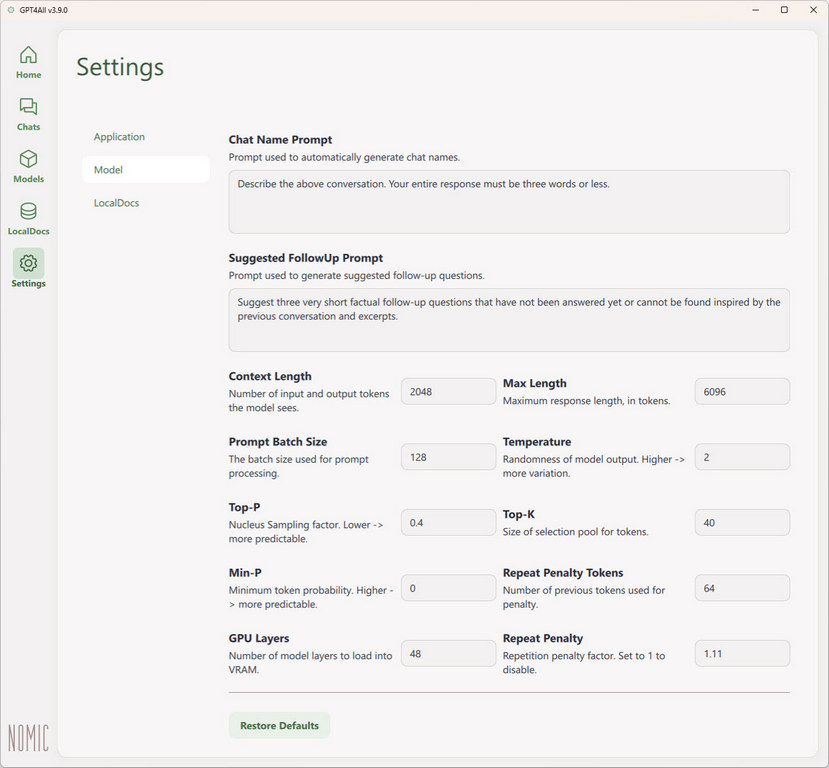
Also, you need to tweak your repeat penalty if your model is hallucinating or repeating endless output loops. You can start from 1.0 and slowly bump the increments by 0.01 adjustments at a time to find the sweet spot. Moreover, the higher temperature setting give you more creative outputs great for creative writing. On the other hand, a lower temperature value below 1-2 gives more predictable outputs from each generation.
Wrapping up, you won’t need to tweak the Top-P or Min-P settings, while the GPU layers is the amount of model layers to load into the faster VRAM, with the rest going to CPU-system RAM. For example, if you have a top-end RTX 4090 consumer GPU with 24GB VRAM, you can offload multiple layers to the GPU for faster processing. If you have multiple GPUs, you can probably offload more layers.
Chat template
Also, the good thing about GGUF formats is that most of the model parameters and chat templates are already embedded into the downloaded GGUF file. This includes a chat template which has to be conformed to a Jinja template. GPT4All requires a Jinja template.
Here is a simple Deekseek R1-compatible chat template to get you started if you are missing one:
{% for message in messages %}
{ % if message[‘role’] == ‘user’ %}{{ message[‘content’] }}{% endif %}
{% if message[‘role’] == ‘assistant’ %}{{ “\nAssistant:\n” + message[‘content’] }}{% endif %}
{ % endfor %}
{% if add_generation_prompt %}
{{ “\nAssistant:\n” }
}
{% endif %}
All in all, that wraps up our quick tutorial intro and setup guide for running DeepSeek R1 on your local computer hardware using ready-made programs like GPT4All. Hope this article fills you in as a quick layman introduction into the world of LLMs. Have fun with your new setup and never stop learning!
{kind=link}